
6、共享池(shared pool)
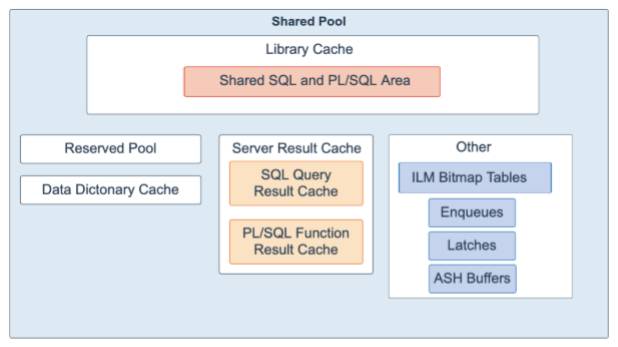
共享池是系统全局区 (SGA) 的组成部分,负责缓存各种类型的程序数据。例如,共享池存储已解析的SQL,PL/SQL代码,系统参数和数据字典信息。共享池⼏乎涉及数据库中发⽣的每个操作。例如,如果⽤户执⾏SQL语句,则Oracle数据库将访问共享池。
共享池分为⼏个⼦组件:
•库⾼速缓存 (Library cache):是⼀种共享池内存结构,⽤于存储可执⾏的 SQL和PL/SQL代码。该缓存包含共享的SQL和PL/SQL区域以及控制结构,例如锁和库缓存句柄。当执⾏SQL语句时,数据库尝试重⽤以前执⾏的代码。如果库⾼速缓存中存在SQL语句的已解析表示形式并且可以共享,则数据库将重⽤代码。此操作称为软解析或库⾼速缓存命中。否则,数据库必须构建应⽤程序代码的新的可执⾏版本,这称为硬解析或库⾼速缓存未命中。
•保留池 (Reserved pool):是共享池中的⼀个内存区域,Oracle数据库可使⽤ 该内存区域来分配连续的⼤块内存。数据库从共享池中按照Chunk⽅式分配内存。Chunk允许将⼤型对象(超过5 KB)加载到缓存中,⽽⽆需单个连续区域。这样,数据库减少了由于碎⽚⽽耗尽连续内存的可能性。
•数据字典⾼速缓存 (Data dictionary cache):存储有关数据库对象的信息(即字典数据)。此缓存也称为⾏缓存,因为它将数据保存为⾏⽽不是缓冲区。
•服务器结果缓存 (Server result cache):是共享池中的⼀个内存池,并保存结果集。服务器结果缓存包含SQL查询结果缓存和PL/SQL函数结果缓存,它们共享相同的基础结构。SQL查询结果缓存存储查询和查询⽚段的结果。⼤多数应⽤程序都受益于这种性能改进。PL/SQL函数结果缓存存储函数结果集。结果缓存的良好候 选者是经常调⽤的函数,这些函数依赖于相对静态的数据。
•其他组件 (Other components):包括队列,锁存器,信息⽣命周期管理 (ILM) 位图表,活动会话历史记录 (ASH) 缓冲区和其他次要内存结构。排队是共享 的内存结构(锁),⽤于序列化对数据库资源的访问。它们可以与会话或事务相关 联。例如:控制⽂件事务,数据⽂件,实例恢复,介质恢复,事务恢复,作业队列等。锁存器⽤作低级序列化控制机制,⽤于保护SGA中的共享数据结构免于同时访问。例如:⾏⾼速缓存对象,库⾼速缓存pin和⽇志⽂件并⾏写⼊。
注意:更多详细信息,请看如下内容:Shared Pool.
7、大池(Large Pool)
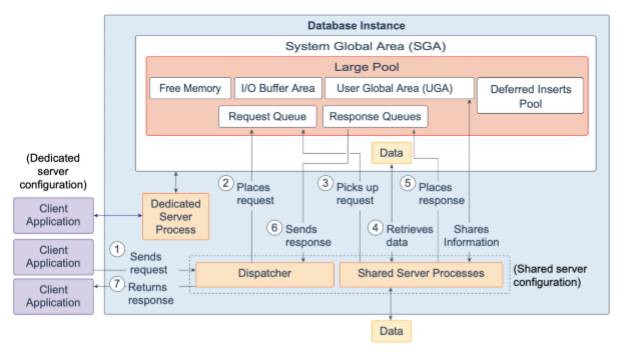
⼤池是数据库管理员可以配置的可选内存区域,可以为以下各项提供⼤内存分配:
•⽤户全局区域 (UGA):共享服务器和Oracle XA接⼝的会话内存(⽤于事务与多个数据库交互)
•I/O 缓冲区 (I/O Buffer Area):I/O服务器进程,并⾏查询操作中使⽤的消息缓冲区,Recovery Manager (RMAN) I/O从属进程的缓冲区,以及存储⾼级排队内存表。
•延迟插⼊池 (Deferred Inserts Pool):快速提取功能可将数据库中定义为MEMOPTIMIZE FOR WRITE的表进⾏⾼频单⾏数据插⼊。快速摄取的插⼊物也称 为延迟插⼊物。它们初在⼤缓冲池中缓冲,然后在每个对象每个会话每次写⼊1MB或60秒后由空间管理协调器 (SMCO) 和Wxxx从属后台进程异步写⼊磁盘。在SMCO后台进程进⾏扫描之前,任何会话(包括写⼊的会话)都⽆法读取该缓冲池中缓冲的任⼀数据,即使已提交的会话。该池在⼤型池中被初始化是在第⼀⾏数据 插⼊memoptimized 表时进⾏。当有⾜够的空间时,将从⼤型池中分配2G。如果⼤型池中没有⾜够的空间,则会在内部发现并⾃动清除ORA-4031,然后使⽤⼀半的 请求内存⼤⼩重试分配。如果⼤型池中仍然没有⾜够的空间,则使⽤512M和256M 重试分配,然后禁⽤该功能,直到重新启动实例。初始化池后,⼤⼩将保持不变。它不能增⻓或收缩。
•可⽤内存
⼤型池与共享池中的保留空间不同,共享池中的保留空间与从共享池分配的其他 内存使⽤相同的近少使⽤ (LRU) 列表。⼤池没有LRU列表。内存已分配,在使⽤完之前⽆法释放。
来⾃⽤户的请求是单个API调⽤,属于⽤户的SQL语句。在专⽤服务器环境中,⼀个服务器进程处理单个客户端进程的请求。每个服务器进程都使⽤系统资源,包括CPU周期和内存。在共享服务器环境中,将发⽣以下操作:
1.客户端应⽤程序向数据库实例发送请求,并且分派进程接收该请求。
2. 分派进程将请求放在⼤池中的请求队列上。
3. 下⼀个可⽤的共享服务器进程将处理该请求。共享服务器进程检查公共请求 队列中是否有新请求,并以先进先出的⽅式接收新请求。⼀个共享服务器进 程在队列中接收⼀个请求。
4. 共享服务器进程对数据库进⾏所有必要的调⽤以完成请求。⾸先,共享服务器进程访问共享池中的库缓存以验证请求的项⽬;例如,它检查表是否存在,⽤户是否具有正确的特权等等。接下来,共享服务器进程访问缓冲区⾼速缓存以检索数据。如果数据不存在,则共享服务器进程将访问磁盘。不同的共享服务器进程可以处理每个数据库调⽤。因此,解析查询,获取第⼀⾏,获取下⼀⾏以及关闭结果集的请求可能分别由不同的共享服务器进程处理。由于不同的共享服务器进程可能会处理每个数据库调⽤,因此⽤户全局区域 (UGA) 必须是共享内存区域,因为UGA包含有关每个客户端会话的信 息。反过来说,UGA包含有关每个客户端会话的信息,并且必须对所有共享服务器进程可⽤,因为任何共享服务器进程都可以处理任何会话的数据库调⽤。
5. 请求完成后,共享服务器进程将响应放置在⼤型池中的呼叫分派进程的响应队列上。每个分派进程都有⾃⼰的响应队列。
6. 响应队列将响应发送到分派进程。
7. 分派进程将完成的请求返回到适当的客户端应⽤程序。
注意:更多详细信息,请看如下内容:Large Pool.
8、数据库高速缓冲区(Database Buffer Cache)
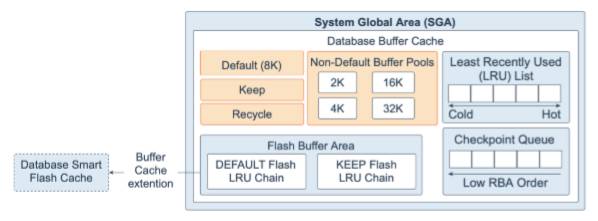
数据库缓冲区⾼速缓存,也称为缓冲区⾼速缓存,是系统全局区域 (SGA) 中的存储区域,⽤于存储从数据⽂件读取的数据块的副本。缓冲区是数据库块⼤⼩的内存 块。每个缓冲区都有⼀个称为数据库缓冲区地址 (DBA) 的地址。同时连接到数据库实例的所有⽤户共享对缓冲区⾼速缓存的访问。缓冲区⾼速缓存的⽬标是优化物理I/O, 并将经常访问的块保留在缓冲区⾼速缓存中,并将不经常访问的块写⼊磁盘。
Oracle数据库⽤户进程第⼀次需要特定数据时,它将在数据库缓冲区⾼速缓存中搜索数据。如果进程发现缓存中已存在的数据(缓存命中),则可以直接从内存中读取数据。如果该进程在缓存中找不到数据(缓存未命中),则它必须在访问数据之前 将数据块从磁盘上的数据⽂件复制到缓存中的缓冲区中。通过缓存命中访问数据⽐通 过缓存未命中访问数据更快。
⾼速缓存中的缓冲区由复杂算法管理,该算法使⽤近少使⽤ (LRU) 列表和 Touch Count算法的组合。LRU有助于确保近使⽤的块倾向于保留在内存中,以 ⼤程度地减少磁盘访问。
数据库⾼速缓冲区包括以下内容:
•默认池 (Default pool):是通常缓存块的位置。默认块⼤⼩为8 KB。除⾮您⼿动配置单独的池,否则默认池是唯⼀的缓冲池。其他池的可选配置对默认池⽆效。
•保留池 (Keep pool):适⽤于经常访问但由于空间不⾜⽽在默认池中过期的块。保留缓冲池的⽬的是在内存中保留指定的对象,从⽽避免I/O操作。
•回收池 (Recycle pool):⽤于不经常使⽤的块。回收池可防⽌指定的对象占⽤缓存中不必要的空间。
•⾮默认缓冲池 (Non-default buffer pools):适⽤于使⽤2 KB,4 KB,16 KB 和32 KB⾮标准块⼤⼩的表空间。每个⾮默认块⼤⼩都有其⾃⼰的池。Oracle数据库以与默认池相同的⽅式管理这些池中的块。
•数据库智能闪存缓存 (Flash cache):使您可以使⽤闪存设备来增加缓冲区缓 存的有效⼤⼩,⽽⽆需添加更多主内存。闪存缓存可以通过将数据库缓存的需频繁 访问的数据存储到闪存中⽽不是从磁盘读取数据来提⾼数据库性能。当数据库请求 数据时,系统⾸先在数据库缓冲区⾼速缓存中查找。如果找不到数据,则系统将在 数据库智能闪存缓存中查找。如果它在那⾥找不到数据,则只会在磁盘存储中查 找。您必须在Oracle Real Application Clusters环境中的所有实例上配置闪存缓存, 或者不配置任何节点的闪存存储。
•最近最少使⽤列表(LRU):包含指向脏缓冲区和⾮脏缓冲区的指针。LRU 列表有⼀个热端和⼀个冷端。冷缓冲区是近未使⽤过的缓冲区。热缓冲区经常被 访问并且近已经被使⽤。从概念上讲,只有⼀个LRU,但是对于数据并发,数据 库实际上使⽤了多个LRU。
•检查点队列 (Checkpoint queue):检查点队列是⼀个链表结构,是由缓冲区 头部结构构成;当数据块被修改后,缓冲区通过此链表结构来跟踪数据块的修改。链表的顺序是根据早应⽤于该数据块的RBA(Redo Block Address)地址排序得到的。
•Flash缓冲区 (Flash Buffer Area):由DEFAULT Flash LRU链和KEEP Flash LRU链组成。如果没有数据库智能闪存缓存,则当进程尝试访问某个块并且该块在 缓冲区缓存中不存在时,该块将⾸先从磁盘读⼊内存(物理读取)。当内存中缓冲 区⾼速缓存已满时,将根据近少使⽤ (LRU) 机制将缓冲区从内存中逐出。使⽤ Database Smart Flash Cache,当⼲净的内存中缓冲区过期时,该缓冲区的内容将通过Database Writer进程 (DBWn) 在后台写⼊闪存中,并且缓冲区头作为元数据保留在内存中DEFAULT闪存或KEEP闪存LRU列表,具体取决于FLASH_CACHE对象属性的值。KEEP闪存LRU列表⽤于将缓冲区头保留在单独的列表上,以防⽌常规缓冲区头替换它们。因此,属于指定为KEEP的对象的闪存缓冲区标头倾向于在闪存缓存中保留更⻓时间。如果将FLASH_CACHE对象属性设置为NONE,则系统不会在闪存缓存或内存中保留相应的缓冲区。当再次访问已过期的内存缓冲区时,系统将检查闪存缓存。如果找到了缓冲区,它将从闪存缓存中读回它,这仅花费从磁 盘读取的时间的⼀⼩部分。跨实时应⽤程序群集 (RAC) 的闪存缓存缓冲区的⼀致性 与缓存融合的维护⽅式相同。因为闪存⾼速缓存是扩展⾼速缓存,并且直接路径I/O 完全绕过了缓冲区⾼速缓存,所以此功能不⽀持直接路径I/O。请注意,系统不会将 脏缓冲区放⼊闪存缓存中,因为它可能必须将缓冲区读取到内存中才能对它们进⾏ 检查点,因为写⼊闪存缓存不会计⼊检查点。
注意:更多详细信息,请看如下内容:Database Buffer Cache.
9、内存中列式存储区(In-Memory Area)
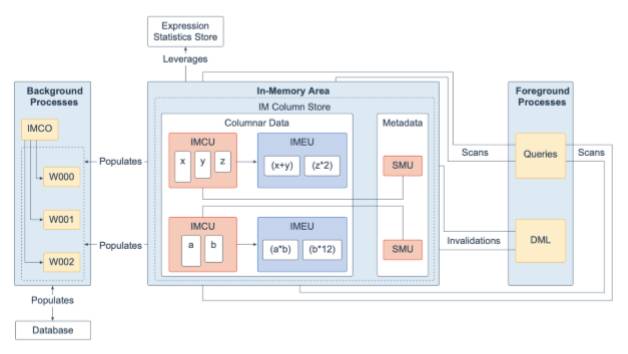
In-Memory存储区是⼀个可选的SGA组件,其中包含内存中列存储(IM列存 储),该存储区使⽤针对快速扫描进⾏了优化的列格式将表和分区存储在内存中。IM 列存储使数据能够以传统的⾏格式(在缓冲区⾼速缓存中)和列格式同时在SGA中填充。数据库透明地将在线事务处理 (OLTP) 查询(例如主键查找)发送到缓冲区⾼速缓存,并将分析和报告查询发送到IM列存储。在获取数据时,Oracle数据库还可以从同⼀查询中的两个内存区域读取数据。双格式体系结构不会使内存需求加倍。缓冲区⾼速缓存经过优化,可以以⽐数据库⼩得多的⼤⼩运⾏。
您应该仅在IM列存储中填充关键的数据。要将对象添加到IM列存储中,请在创建或更改对象时为该对象打开INMEMORY属性。您可以在表空间(对于表空间中的所 有新表和视图),表,(⼦)分区,物化视图或对象内的列⼦集上指定此属性。
IM列存储以优化的存储单元(⽽不是传统的Oracle数据块)管理数据和元数据。内存中压缩单元 (IMCU) 是⼀种压缩的只读存储单元,其中包含⼀个或多个列的数 据。快照元数据单元 (SMU) 包含相关IMCU的元数据和事务信息。每个IMCU都映射到 ⼀个单独的SMU。
表达式统计信息存储 (ESS) 是⼀个存储有关表达式评估的统计信息的存储库。ESS驻留在SGA中,并且也保留在磁盘上。启⽤IM列存储后,数据库会将ESS⽤于其 内存中表达式(IM表达式)功能。内存中表达单元 (IMEU) 是⽤于存储实现的IM表达式和⽤户定义的虚拟列的存储容器。请注意,ESS独⽴于IM列存储。ESS是数据库的永久组件,不能禁⽤。
从概念上讲,IMEU是其⽗IMCU的逻辑扩展。就像IMCU可以包含多个列⼀样,IMEU可以包含多个虚拟列。每个IMEU都恰好映射到⼀个IMCU,映射到同⼀⾏集。IMEU包含与其关联的IMCU中包含的数据的表达结果。填充IMCU后,还将填充关联 的IMEU。
典型的IM表达式包含⼀列或多列(可能带有常量),并且与表中的⾏具有⼀对⼀的映射关系。例如,⼀个EMPLOYEES表的IMCU包含Weekly_salary列的1-1000⾏。对于此IMCU中存储的⾏,IMEU计算⾃动检测到的IM表达式weekly_salary * 52,并将 ⽤户定义的虚拟列Quarterly_salary定义为weekly_salary * 12。IMCU中的第三⾏下映 射到IMEU中的第三⾏下。
In-Memory区细分为两个池:⼀个1MB列式数据池,⽤于存储填充到内存中的实 际列格式数据 (IMCU和IMEU),以及⼀个64K元数据池,⽤于存储有关对象的元数 据。填充到IM列存储中。这两个库的相对⼤⼩由内部启发算法确定。In-Memory区中 的⼤部分内存都分配给1MB池。内存区域的⼤⼩由初始化参数INMEMORY_SIZE(默认值为0)控制,并且⼩⼤⼩必须为100MB。从Oracle Database 12.2开始,您可以通过ALTER SYSTEM命令将INMEMORY_SIZE参数增加⾄少128MB,来动态增加内存 区域的⼤⼩。请注意,⽆法动态缩⼩内存区域的⼤⼩。
In-Memory表在⾸次访问表数据或数据库启动时会获取在IM列存储中分配的IMCU。通过从磁盘格式转换为新的内存列式格式,可以创建表的内存副本。每次实例重新启动时都会完成此转换,因为IM列存储副本仅驻留在内存中。完成此转换后,表 的内存版本逐渐可⽤于查询。如果对表进⾏了部分转换,则查询能够使⽤部分内存版本并转到磁盘进⾏其余操作,⽽不必等待整个表都被转换。
为了响应查询和数据操作语⾔ (DML),服务器进程扫描列数据并更新SMU元数据。后台进程将磁盘中的⾏数据填充到IM列存储中。In-Memory协调进程 (IMCO) 是启动后台填充和重新填充列式数据的后台进程。空间管理协调进程 (SMCO) 和空间管理⼯作进程 (Wnnn) 是后台进程,它们代表IMCO实际填充和重新填充数据。DML块更改将写⼊缓冲区⾼速缓存,然后再写⼊磁盘。然后,后台进程根据元数据失效和查询请求将磁盘中的⾏数据重新填充到IM列存储中。
您可以启⽤ In-Memory 快速启动功能,以将IM列存储中的列数据以压缩列格式写回到数据库中的表空间。此功能使数据库启动更快。请注意,此功能不适⽤于 IMEU,它们总是从IMCU动态填充。
注意:更多详细信息,请看如下内容:Introduction to Oracle Database In-Memory.
10、数据库数据文件(Database Data Files)
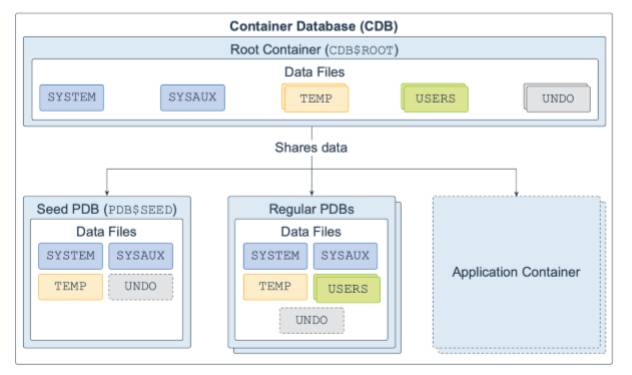
数据库是⼀组存储⽤户数据和元数据的物理⽂件。元数据由有关数据库服务器的结构,配置和控制信息组成。您可以将数据库设计为多租户容器数据库 (CDB) 或⾮容器数据库 (non-CDB)(20c中只⽀持多租户结构)。
CDB由⼀个CDB根容器(也称为根),唯⼀的⼀个种⼦可插⼊数据库(种⼦ PDB),零个或多个⽤户创建的可插拔数据库(简称为PDB)以及零个或多个应⽤程序容器组成。整个CDB称为系统容器。对于⽤户或应⽤程序,PDB在逻辑上显示为单 独的数据库。
CDB根容器名为CDB $ ROOT,包含多个数据⽂件,控制⽂件,重做⽇志⽂件, 闪回⽇志和归档的重做⽇志⽂件。数据⽂件存储与所有PDB共享的Oracle提供的元数 据和普通⽤户(每个容器中已知的⽤户)。
种⼦PDB名为PDB $ SEED,是系统提供的PDB模板,其中包含可⽤于创建新 PDB的多个数据⽂件。
常规PDB包含多个数据⽂件,这些⽂件包含⽀持应⽤程序所需的数据和代码。例 如,⼈⼒资源应⽤程序。⽤户仅与PDB交互,⽽不与种⼦PDB或根容器交互。您可以在CDB中创建多个PDB。多租户体系结构的⽬标之⼀是每个PDB与应⽤程序具有⼀对 ⼀的关系。
应⽤程序容器是CDB中⽤于存储应⽤程序数据的PDB的可选集合。创建应⽤程序 容器的⽬的是拥有独⼀的主应⽤程序定义。CDB中可以有多个应⽤程序容器。
数据库分为称为表空间的逻辑存储单元,这些逻辑存储单元共同存储所有数据库 数据。每个表空间由⼀个或多个数据⽂件构成。根容器和常规PDB具有SYSTEM, SYSAUX,USERS,TEMP和UNDO表空间(在常规PDB中为可选)。种⼦PDB具有 SYSTEM,SYSAUX,TEMP和可选的UNDO表空间。
注意:更多详细信息,请看如下内容:Introduction to the Multitenant Architecture.
文章正在更新,敬请期待下文~
- 还没有人评论,欢迎说说您的想法!